![]() It has been a long while since I’ve posted on this blog, because, well, it’s been a busy summer. Let me give you the short of it: TNTLAB has moved to the University of Minnesota.
It has been a long while since I’ve posted on this blog, because, well, it’s been a busy summer. Let me give you the short of it: TNTLAB has moved to the University of Minnesota.
My last post was April 27, which was about a week after the Spring 2018 SIOP conference in Chicago. That timing is not coincidental, as it was only about a week before that conference that I accepted the job offer to move from Old Dominion University (ODU) to the University of Minnesota. It has been a bit of a whirlwind since then, and I feel like I should get my feelings on paper (or equivalent). So this post will be a little more journal-ish than usual (please forgive my self-indulgence) and also quite long. I hope though that it will capture some of the complex feelings and issues associated with moving from one tenure-track I/O position to another, which is something for which I found no resources when I tried to hunt for them this summer. It is a bit like your first academic job, except that you a bit better understand what you’re bringing on top of yourself.
Some History
It’s a bit weird to be at Minnesota, because I actually graduated from Minnesota with a Ph.D. in I/O psychology in 2009, and have thus been away for 9 years. When I was here then, the consistent faculty were Paul Sackett (my adviser), John P Campbell, Deniz Ones, and Joyce Bono. Steve Motowidlo was there when I started but left after a year or two, taking one student in my cohort with him. Nathan Kuncel started toward the end. So that is the Minnesota I remember.

After I graduated, I started a tenure-track job at Old Dominion University in I/O with Debbie Major, Karin Orvis, and Don Davis. Thus, I’ve spent my entire time away from Minnesota as faculty at ODU, where I achieved tenure a few years ago. In that time, I saw (and helped with) some significant transformations in that program; at the end, Debbie had become an Associate Dean, Karin had left, Don had retired, and Konstantin Cirgularov, Xiaoxiao Hu, and Violet Xu had joined, making me the most senior faculty member in the area as of Fall 2017. There was clearly an expectation that I was moving into an “area head” sort of role as of the time I left, which I still feel a significant degree of guilt about.
Why I Had Considered Moving
I had always been a hair dissatisfied with my position at ODU, not because of my colleagues, but because of the climate and resources of the university and our college. ODU’s psychology program, like Georgia Tech’s and a handful of others, is housed in a College of Sciences instead of a College of Liberal Arts, which brings with it the values of the natural sciences. That means different things in different universities. When I interviewed with the (since-let-go-for-related-reasons) dean of the college in 2009, he mentioned that Oceanography had recently bought a $1 million submarine on a grant and asked how I planned to compete with that, a tall order for an I-O. Thus, I spent a now-regrettable amount of time thinking about how to make ODU more money instead of how to build my own research program. It gave me a lot of experience with the NSF and the grant-earning process – which is useful, to be sure – but it was also quite overwhelming, having had no grant training whatsoever while I was a graduate student.
This is not to say that ODU is a bad place to work. Instead, I say it to emphasize the impact of office politics on the career trajectory of an academic. This sort of thing happens everywhere. That dean’s priority was grants; there was no ambiguity in this. If you did not have the potential for grants, or a grant record, you could be denied, discouraged, etc. in regards to career advancement, i.e., tenure, and that shapes the sort of research you find yourself doing. As I mentioned earlier, that dean has since been removed from his position, so things are a bit different now. But it still shaped my “growing up,” so to speak, and had left a persistent case of “that grass is probably greener” that I found difficult to shake.

At least the dean never put the lab on double-secret probation (Animal House).
As a result, I had applied to and interviewed for other jobs on and off throughout my time there. It wasn’t entirely due to this niggling dissatisfaction though; this is also related to one of those open secrets in academia; the only way to get a decent raise, or more resources, or really anything else you might want is to get an external job offer. As a pre-tenure faculty member (and even afterward), it is frankly unwise not to try to get another job, however disloyal and uncomfortable that makes you feel. This is especially salient to I/Os given research on lifetime earning potential related to your salary at your first job; that first job sets a salary trajectory that tends to follow you for the rest of your life. Missing a $10K salary bump by forcing your university to compete with an external job offer can result in millions of dollars of lifetime earnings lost. The only way to escape it in academia is to get two job offers simultaneously. So it’s best to act early.
Unfortunately (I thought at the time), none of those jobs worked out for one reason or another. I interviewed at a few business schools and found the cultures insufferable: an incredible amount of attention paid to the “caliber” of journal people publish in as measured by impact factors. Most business schools even had “the list” of journals that it was acceptable to publish in. This entire idea makes me bristle. It is essentially all of the worst aspects of goal setting; you encourage people to optimize their behavior not on what is actually good for them personally, good for their university, good for society, etc., but what is good for getting a high impact factor, i.e., incremental growth of well-established theories. It also directly encourages the factors that led to the replication crisis, and more subtly, it encourages people to research “safe” topics that they know will get them published in those journals. It diminishes the role of creativity in social science. As a consequence, it is a major reason why most current OB research as published in places like AMJ or JOM is essentially useless to any real live human being working in management. The whole approach is simply against my core values; so I stopped looking too seriously at business schools. Importantly, there are some specific OB programs that do not fall in this trap, but I find they are pretty rare.
I also interviewed at a few I/O programs, with varying levels of success, but often had the same problem: philosophical disagreements. One of the things that is not very obvious as a graduate student is that individual graduate programs have ingrained cultures that are both shaped by faculty behavior and shape that behavior. It is a self-promoting cycle of behavior, and it crosses area lines. So just like ODU had a “grants-first” attitude across the College of Sciences because of the dean at that time, I encountered programs that were basically business-lite; all theory, all the time, with very little attention paid to the real world. I didn’t like that much either, because it seems directly contrary to what I see as I/O’s core values.
The Invitation

Good luck with that.
When I was invited to apply to the Minnesota job, I was immediately interested. The faculty here still create theory, but that theory is in service to a particular problem that needs solving. I was also immediately skeptical, because I didn’t think I had a snowball’s chance in hell of getting the job. Applying felt like a moonshot. I even emailed Paul and asked if he was sure I was supposed to have been on the email invitation list and got an answer I wasn’t expecting: yes, because they were looking for complementary skill sets to those already in the area. They did not want another Paul, Deniz, Nathan, or Aaron Schmidt (who had joined after I graduated). They wanted something new.
At this point, let me give you a bit of additional self-disclosure that might clarify my skepticism. I am an interdisciplinary researcher. I try to blend fields, mostly I-O with human-computer interaction or computer science, and create something new. That means, quite frankly, that it is more difficult to publish in the traditional “top tier” outlets of any of the fields I integrate. The reasons for this are complicated, and not worth going into too much detail here, but the core of it is (again) value differences. The aspects of research that computer scientists find “top tier” worthy are not the same as the ones that I/Os do. A lot of what I/O does in its top tier outlets seems completely inconsequential to a computer scientist; when I talk about I/O research to that crowd, I hear a lot of “why would anyone care about that?” and “can’t the problem be fixed with different software?” The reverse is also true.
That means when publishing this sort of research, you must make a choice: do I publish in a well-respected interdisciplinary journal that people in the two component fields probably won’t read or do I try to tailor it to one of the fields at the expense of the other? This is not a meta-question most I/Os need to ask themselves. I have generally tended toward interdisciplinary journals and have done pretty well with it. But the result is that I have most of a reputation within the particular interdisciplinary communities I publish in (primarily games and gamification) and less so within the I/O community itself, at least as far as publishing goes. This also has some strong “impact factor” implications, which I don’t care about personally but many people do. So let me just say I was surprised when Paul indicated that difference in approach, perspective, and skill set, despite these downsides in terms of “program stats,” is actually what they were looking for.

The man himself, judging both of us.
The specific then-open position was created as a result of John P. Campbell’s retirement. If you’re an I/O, you know who this is. If you think of job performance as a behavior and differentiate it from effectiveness, that is thanks to John. If you think of performance as the results of declarative knowledge, procedural knowledge and and skill, and motivation, that is thanks to John. If you think of performance as something you can break down into eight categories of behavior, that is thanks to John. His accomplishments are significant and varied, and this just scratches the surface. He is a giant in the field.
So as a result of John’s retirement, the remaining faculty at Minnesota solicited donations to create an endowed chair: the John P. Campbell Distinguished Professorship in Industrial and Organizational Psychology. After an invitation to apply, a job interview, and several tense weeks of negotiation, that is the job I now hold. It is frankly a bit intimidating to follow in such footsteps. But where I think John and I share a philosophy it is in our willingness to challenge the status quo when we believe something with conviction. Just as John challenged people to rethink what job performance is at a time when people felt just peachy about supervisory ratings, I contend that the ways I/O tends to think about the role and importance of technology in workplace behavior is very wrong, that it betrays some fundamental misunderstandings of what technology is, why it exists, and how it is created by, interfaces with, and affects humans in turn.
The Move
Since agreeing to take this position, I spent the summer finding a house and moving and am still in the midst of moving into my research lab. The most recent issue is that the flooring in what will become my main lab as it turns out is full of asbestos! It’s being removed this week in fact. This is only the most recent in a long string of challenges in setting up a new lab from the ashes of an old one, but that’s another (long) post, perhaps for later.
I was fortunate to be able to bring two students with me: Elena Auer and Sebastian Marin. Elena had taken over as my lab manager at ODU, so her being able to come to Minnesota is a bit of a godsend. If you get no advice out of this post except one nugget, it’s this one: don’t move your lab alone, if you can avoid it. Having (at least) a second person creates a sense of continuity that will keep you grounded. Otherwise, it’s easy to lose yourself in the new university system. But do be keenly aware that whereas you made the choice to upend your own life and research to move, you are inflicting this choice upon your graduate students. Even if the move is better for you, it’s not always better for them. To try to even the balance a little, I built in a few years of GRA funding into my startup budget for both of them; and frankly, it’s the least I could do.
The sheer scope difference in terms of complexity has been particularly salient for me. Minnesota is a traditional “R1.” ODU was trying to move in that direction, but it was not there yet when I left. And honestly, I didn’t realize how far it had to go until moving here, where the sheer scope of internal resources and staff available for research support is a bit staggering. For example, 110,000 hours of computing time on a supercomputer is the “free tier” of service here per lab per year; but if you give them a paragraph justifying why you need it, they’ll give you 440,000 hours! (For reference, entire research projects for us tend to use less than 500). The disparity in resources also makes a lot of the comments we received on NSF applications over the years make a lot more sense, e.g., “I am not sure this university has the resources to support a project like this.” Incidentally, it does, but it definitely would’ve required a lot more work on my part than if we’d done it at Minnesota.
Thus, the change is ultimately very much to our advantage even if we are trapped in moving hell right now. In terms of some specific gains, one, we get to use that supercomputer for our artificial intelligence work. ODU had one too, but it was smaller in scope, and as a result, not particularly social-scientist-friendly, which is not at all true here. Two, there is a respect for research in administration that makes resource allocation much less of an issue relatively-speaking; there seems to always people or units or other systems to meet particular needs. Three, and most excitingly to me, I am building a whole-room VR lab to play with! VR is still in its infancy, but some key areas of advantage versus traditional approaches have begun to take shape in the selection and training domains that I want to test here. And as an added benefit, it’s a ton of fun.
Conclusion
 TNTLAB is still mid-transition, but we’re getting closer every day back to “normal operations” every day. I think we will be more productive than ever before; the lab has already grown larger people-wise than it was at ODU. I will chronicle some of this on the blog so that you can see the growth yourself, if you are curious enough to indulge me again!
TNTLAB is still mid-transition, but we’re getting closer every day back to “normal operations” every day. I think we will be more productive than ever before; the lab has already grown larger people-wise than it was at ODU. I will chronicle some of this on the blog so that you can see the growth yourself, if you are curious enough to indulge me again!
In this post, I’m going to demonstrate how to conduct a simple NLP analysis (topic modeling using latent Dirichlet allocation/LDA) using data from Twitter using the #siop18 hashtag. What I would like to know is this: what topics emerged on Twitter related to this year’s conference? I used R Markdown to generate this post.
To begin, let’s load up a few libraries we’ll need. You might need to download these first! After we get everything loaded, we’ll dig into the process itself.
library(tm)
library(tidyverse)
library(twitteR)
library(stringr)
library(wordcloud)
library(topicmodels)
library(ldatuning)
library(topicmodels)Challenge 1: Getting the Data into R
To get data from Twitter into R, you need to log into Twitter and create an app. This is easier than it sounds.
- Log into Twitter.
- Go to http://apps.twitter.com and click Create New App.
- Complete the form and name your app whatever you want. I named mine rnlanders R Interface.
- Once you have created your app, open its settings and navigate to Keys and Access Tokens.
- Copy-paste the four keys you see into the block of code below.
# Replace these with your Twitter access keys - DO NOT SHARE YOUR KEYS WITH OTHERS
consumer_key <- "xxxxxxxxxxxx"
consumer_secret <- "xxxxxxxxxxxxxxxxxxxxxxxx"
access_token <- "xxxxxxxxxxxxxxxxxxxxxxxx"
access_token_secret <- "xxxxxxxxxxxxxxxxxxxxxxxx"
# Now, authorize R to use Twitter using those keys
# Remember to select "1" to answer "Yes" to the question about caching.
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_token_secret)Finally, we need to actually download all of those data. This is really two steps: download tweets as a list, then convert the list into a data frame. We’ll just grab the most recent 2000, but you could grab all of them if you wanted to.
twitter_list <- searchTwitter("#siop18", n=2000)
twitter_tbl <- as.tibble(twListToDF(twitter_list))Challenge 2: Pre-process the tweets, convert into a corpus, then into a dataset
That text is pretty messy – there’s a lot of noise and nonsense in there. If you take a look at a few tweets in twitter_tbl, you’ll see the problem yourself. To deal with this, you need to pre-process. I would normally do this in a tidyverse magrittr pipe but will write it all out to make it a smidge clearer (although much longer).
Importantly, this won’t get everything. There is a lot more pre-processing you could do to get this dataset even cleaner, if you were going to use this for something other than a blog post! But this will get you most of the way there, and close enough that the analysis we’re going to do afterward won’t be affected.
# Isolate the tweet text as a vector
tweets <- twitter_tbl$text
# Get rid of retweets
tweets <- tweets[str_sub(tweets,1,2)!="RT"]
# Strip out clearly non-English characters (emoji, pictographic language characters)
tweets <- str_replace_all(tweets, "\\p{So}|\\p{Cn}", "")
# Convert to ASCII, which removes other non-English characters
tweets <- iconv(tweets, "UTF-8", "ASCII", sub="")
# Strip out links
tweets <- str_replace_all(tweets, "http[[:alnum:][:punct:]]*", "")
# Everything to lower case
tweets <- str_to_lower(tweets)
# Strip out hashtags and at-mentions
tweets <- str_replace_all(tweets, "[@#][:alnum:]*", "")
# Strip out numbers and punctuation and whitespace
tweets <- stripWhitespace(removePunctuation(removeNumbers(tweets)))
# Strip out stopwords
tweets <- removeWords(tweets, stopwords("en"))
# Stem words
tweets <- stemDocument(tweets)
# Convert to corpus
tweets_corpus <- Corpus(VectorSource(tweets))
# Convert to document-term matrix (dataset)
tweets_dtm <- DocumentTermMatrix(tweets_corpus)
# Get rid of relatively unusual terms
tweets_dtm <- removeSparseTerms(tweets_dtm, 0.99)Challenge 3: Get a general sense of topics based upon word counts alone
Now that we have a dataset, let’s do a basic wordcloud visualization. I would recommend against trying to interpret this too closely, but it’s useful to double-check that we didn’t miss anything (e.g., if there was a huge “ASDFKLAS” in this word cloud, it would be a signal that I did something wrong in pre-processing). It’s also great coffee-table conversation?
# Create wordcloud
wordCounts <- colSums(as.tibble(as.matrix(tweets_dtm)))
wordNames <- names(as.tibble(as.matrix(tweets_dtm)))
wordcloud(wordNames, wordCounts, max.words=75)
# We might also just want a table of frequent words, so here's a quick way to do that
tibble(wordNames, wordCounts) %>% arrange(desc(wordCounts)) %>% top_n(20)## # A tibble: 20 x 2
## wordNames wordCounts
## <chr> <dbl>
## 1 session 115
## 2 great 75
## 3 work 56
## 4 chicago 51
## 5 get 49
## 6 one 46
## 7 day 43
## 8 can 43
## 9 like 42
## 10 thank 42
## 11 use 42
## 12 learn 42
## 13 dont 41
## 14 amp 41
## 15 today 40
## 16 see 40
## 17 siop 37
## 18 look 36
## 19 confer 35
## 20 new 34These stems reveal what you’d expect: most people talking about #siop18 are talking about conference activities themselves – going to sessions, being in Chicago, being part of SIOP, looking around seeing things, etc. A few stick out, like thank and learn.
Of course, this is a bit of an exercise in tea-leaves reading, and there’s a huge amount of noise since people pick particular words to express themselves for a huge variety of reasons. So let’s push a bit further. We want to know if patterns emerge within these words surrounding latent topics.
Challenge 4: Let’s see if we can statistically extract some topics and interpret them
For this final analytic step, we’re going to run latent Dirichlet allocation (LDA) and see if we can identify some latent topics. The dataset is relatively small as far as LDA goes, but perhaps we’ll get something interesting out of it!
First, let’s see how many topics would be ideal to extract using ldatuning. I find it useful to do two of these in sequence, to get the “big picture” and then see where a precise cutoff might be best.
# First, get rid of any blank rows in the final dtm
final_dtm <- tweets_dtm[unique(tweets_dtm$i),]
# Next, run the topic analysis and generate a visualization
topic_analysis <- FindTopicsNumber(final_dtm,
topics = seq(2,100,5),
metrics=c("Griffiths2004","CaoJuan2009","Arun2010","Deveaud2014"))
FindTopicsNumber_plot(topic_analysis)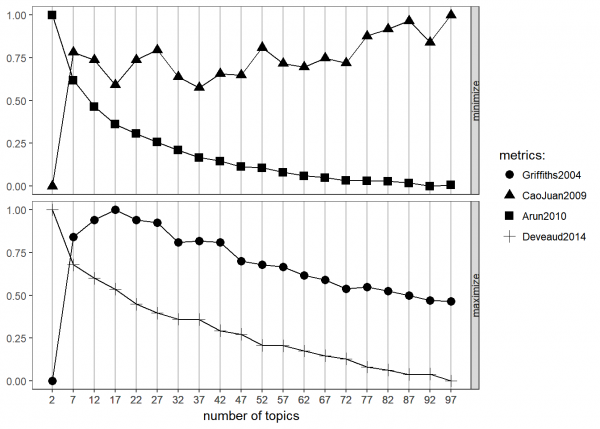
The goal of this analysis is to find the point at which the various metrics (or the one you trust the most) is either minimized (in the case of the top two metrics) or maximized (in the case of the bottom two). It is conceptually similar to interpreting a scree plot for factor analysis.
As is pretty common in topic modeling, there’s no great answer here. Griffiths suggests between 10 and 25 somewhere, Cao & Juan suggests the same general range although noisier, Arun is not informative, nor is Deveaud. This could be the result of poor pre-processing (likely contributes, since we didn’t put a whole lot of effort into spot-checking the dataset to clean it up completely!) or insufficient sample size (also likely) or just a noisy dataset without much consistency. Given these results, let’s zoom in on 10 to 25 with the two approaches that seem to be most helpful.
topic_analysis <- FindTopicsNumber(final_dtm,
topics = seq(10,26,2),
metrics=c("Griffiths2004","CaoJuan2009"))
FindTopicsNumber_plot(topic_analysis)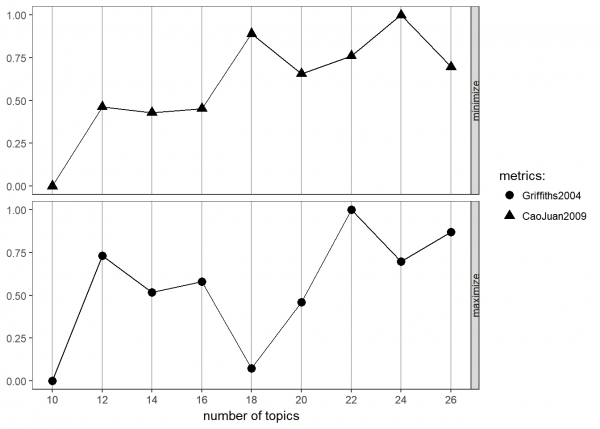
These are both very noisy, but I’m going to go with 18. In real-life modeling, you would probably want to try values throughout this range and try to interpret what you find within each.
Now let’s actually run the final LDA. Note that in a “real” approach, we might use a within-sample cross-validation approach to develop this model, but here, we’re prioritizing demonstration speed.
# First, conduct the LDA
tweets_lda <- LDA(final_dtm, k=18)
# Finally, list the five most common terms in each topic
tweets_terms <- as.data.frame(tweets_lda@beta) %>% # grab beta matrix
t %>% # transpose so that words are rows
as.tibble %>% # convert to tibble (tidyverse data frame)
bind_cols(term = tweets_lda@terms) # add the term list as a variable
names(tweets_terms) <- c(1:18,"term") # rename them to numbers
# Visualize top term frequencies
tweets_terms %>%
gather(key="topic",value="beta",-term,convert=T) %>%
group_by(topic) %>%
top_n(10, beta) %>%
select(topic, term, beta) %>%
arrange(topic,-beta) %>%
print(n = Inf)## # A tibble: 180 x 3
## # Groups: topic [18]
## topic term beta
## <int> <chr> <dbl>
## 1 1 chicago -1.32
## 2 1 confer -1.98
## 3 1 home -2.70
## 4 1 bring -3.07
## 5 1 day -3.28
## 6 1 back -3.79
## 7 1 siop -3.97
## 8 1 work -4.01
## 9 1 time -4.03
## 10 1 morn -4.22
## 11 2 research -2.80
## 12 2 session -3.27
## 13 2 can -3.40
## 14 2 need -3.45
## 15 2 work -3.51
## 16 2 team -3.65
## 17 2 booth -3.79
## 18 2 get -3.82
## 19 2 come -3.94
## 20 2 your -3.94
## 21 3 can -3.12
## 22 3 differ -3.26
## 23 3 get -3.37
## 24 3 dont -3.44
## 25 3 your -3.46
## 26 3 great -3.47
## 27 3 good -3.51
## 28 3 today -3.63
## 29 3 see -3.75
## 30 3 organ -3.80
## 31 4 great -2.70
## 32 4 session -2.78
## 33 4 year -3.45
## 34 4 siop -3.61
## 35 4 see -3.63
## 36 4 work -3.63
## 37 4 amp -3.67
## 38 4 take -3.72
## 39 4 morn -3.73
## 40 4 mani -3.83
## 41 5 session -2.37
## 42 5 one -2.79
## 43 5 can -3.14
## 44 5 work -3.50
## 45 5 manag -3.69
## 46 5 amp -3.92
## 47 5 peopl -3.92
## 48 5 day -3.96
## 49 5 great -4.00
## 50 5 develop -4.05
## 51 6 cant -2.96
## 52 6 one -2.96
## 53 6 say -3.03
## 54 6 wait -3.10
## 55 6 now -3.40
## 56 6 today -3.52
## 57 6 learn -3.53
## 58 6 data -3.66
## 59 6 can -3.69
## 60 6 let -3.71
## 61 7 social -2.40
## 62 7 great -3.05
## 63 7 know -3.36
## 64 7 assess -3.50
## 65 7 session -3.51
## 66 7 now -3.61
## 67 7 will -3.62
## 68 7 job -3.72
## 69 7 use -3.80
## 70 7 back -3.84
## 71 8 session -2.07
## 72 8 great -2.84
## 73 8 learn -2.99
## 74 8 like -3.08
## 75 8 research -3.35
## 76 8 look -3.81
## 77 8 work -4.04
## 78 8 peopl -4.09
## 79 8 today -4.10
## 80 8 still -4.19
## 81 9 like -2.99
## 82 9 day -3.06
## 83 9 way -3.31
## 84 9 tri -3.39
## 85 9 room -3.44
## 86 9 session -3.62
## 87 9 think -3.70
## 88 9 want -3.84
## 89 9 booth -3.87
## 90 9 know -3.88
## 91 10 take -2.69
## 92 10 good -3.15
## 93 10 dont -3.20
## 94 10 game -3.27
## 95 10 siop -3.36
## 96 10 analyt -3.48
## 97 10 need -3.51
## 98 10 research -3.51
## 99 10 look -3.57
## 100 10 new -3.64
## 101 11 work -2.92
## 102 11 engag -3.15
## 103 11 session -3.27
## 104 11 learn -3.37
## 105 11 can -3.61
## 106 11 great -3.67
## 107 11 employe -3.69
## 108 11 amp -3.73
## 109 11 get -3.79
## 110 11 year -3.90
## 111 12 use -2.37
## 112 12 question -3.16
## 113 12 one -3.24
## 114 12 twitter -3.26
## 115 12 busi -3.30
## 116 12 thing -3.35
## 117 12 leader -3.36
## 118 12 day -3.56
## 119 12 data -3.65
## 120 12 learn -3.79
## 121 13 student -3.21
## 122 13 work -3.24
## 123 13 present -3.34
## 124 13 look -3.43
## 125 13 new -3.48
## 126 13 employe -3.54
## 127 13 see -3.81
## 128 13 want -3.83
## 129 13 make -3.86
## 130 13 organ -4.00
## 131 14 committe -2.97
## 132 14 like -3.34
## 133 14 come -3.45
## 134 14 join -3.46
## 135 14 thank -3.53
## 136 14 discuss -3.54
## 137 14 work -3.58
## 138 14 now -3.58
## 139 14 present -3.62
## 140 14 dont -3.66
## 141 15 great -2.56
## 142 15 session -2.59
## 143 15 thank -3.10
## 144 15 like -3.26
## 145 15 new -3.39
## 146 15 today -3.49
## 147 15 employe -3.70
## 148 15 booth -3.86
## 149 15 back -3.87
## 150 15 dont -3.91
## 151 16 see -2.65
## 152 16 thank -3.17
## 153 16 focus -3.19
## 154 16 siop -3.20
## 155 16 session -3.31
## 156 16 help -3.56
## 157 16 get -3.56
## 158 16 amp -3.58
## 159 16 assess -3.76
## 160 16 work -3.82
## 161 17 get -2.60
## 162 17 day -3.05
## 163 17 today -3.30
## 164 17 field -3.34
## 165 17 come -3.65
## 166 17 last -3.66
## 167 17 learn -3.86
## 168 17 peopl -3.95
## 169 17 phd -3.96
## 170 17 good -3.97
## 171 18 session -2.98
## 172 18 realli -3.24
## 173 18 thank -3.24
## 174 18 poster -3.29
## 175 18 time -3.41
## 176 18 think -3.65
## 177 18 look -3.66
## 178 18 best -3.68
## 179 18 present -3.77
## 180 18 talk -3.79There’s a bit of tea-leaves-reading here again, but now instead of trying to interpret individual items, we are trying to identify emergent themes, similar to what we might do with an exploratory factor analysis.
For example, we might conclude something like:
- Theme 1 seems related to travel back from the conference (chicago, conference, home, back, time).
- Theme 2 seems related to organizational presentations of research (research, work, team, booth).
- Theme 7 seems related to what people will bring back to their jobs (social, assess, use, job, back).
- Theme 9 seems related to physical locations (room, session, booth).
- Theme 11 seems related to learning about employee engagement (work, engage, session, learn, employee).
- Theme 14 seems related to explaining SIOP committee work (committee, like, join, thank, discuss, present).
And so on.
At this point, we would probably want to dive back into the dataset to check out interpretations against the tweets that were most representative of their categories. We might even cut out a few high-frequency words (like “work” or “thank” or “poster”) because they may be muddling the topics due to their high frequencies. Many options. But it is important to treat it as a process of iterative refinement. No quick answers here; human interpretation is still central.
In any case, that’s quite enough detail for a blog post! So I’m going to cut if off there.
I hope that despite the relatively rough approach taken here, this has demonstrated to you the complexity, flexibility, and potential value of NLP and topic modeling for interpreting unstructured text data. It is an area you will definitely want to investigate for your own organization or research.
Every year, I post some screenshots of my insane schedule for seeing all of the technology-related content at the annual conference of the Society for Industrial and Organizational Psychology (SIOP). As began in earnest last year, the technology program this year is sizable too. Yet my schedule is even worse than last year somehow, and after accounting for all of my scheduled meetings and sessions in which I’m presenting, I had a grand total of three conference slots open to attend presentations of my own choosing. One of them, I chose to sleep!
So, if you’re interested in technology in I-O psychology at SIOP 2018, let me tell you what I’m doing so that you can attend! I’m excited about all of these, and I’m centrally involved in all but two of them. If you come to any, please find me and say hello! I’ll also be active on Twitter as usual.
- Pre-Conference Workshop: Modern Analytics for Data Big and Small on Wednesday, April 18, both AM and PM workshops. Dan Putka (HumRRO) and I will be given a practical workshop on modern techniques for data acquisition (web scraping/APIs), processing of unstructured text data (natural language processing), and advanced predictive modeling (supervised machine learning) and their applications to I-O science and practice. I’ve heard we are almost full but believe there are still a few slots available!
- Technology in Assessment Community of Interest on Thursday, April 19 at 10:00 AM in Mayfair. Have you been feeling lost lately in regards to tech in assessment in I-O? Does it seem like the research literature is so ancient that it feels like it’s from another era? Do you want to help fix that, and become part of a community of like-minded researchers and practitioners? If so, come to this session! Our goal is to work through some of the biggest issues in a high-level pass at discussion, with the goal of seeding some activities for a longer-term, more permanent virtual community of assessment tech researchers and practitioners! Join us!
- SIOP Select: I-O Igniting Innovation on Thursday, April 19 at 12:00PM in Sheraton 5. In this invited SIOP session, I’ll be introducing a panel of experts in the area of innovation, particularly including I-Os and non-I-Os that have worked in startups! Come hear how I-O can and do contribute to Silicon Valley.
- SIOP Select: TeamSIOP Gameshow Battle for the TeamSIOP Theme Track Championship on Thursday, April 19 at 1:30PM in Sheraton 5. I don’t want to spoil the surprise on what this is, but if you want to be on a game show at SIOP, this is your chance!
- Recruitment in Today’s Workplace Community of Interest on Thursday, April 19 at 4:30PM in Mayfair. In this community of interest, let’s discuss how recruitment has fully entered the digital era and what I-O needs to do to stay on top of the changes afoot.
- Using Natural Language Processing to Measure Psychological Constructs on Friday, April 20 at 8:00AM in Sheraton 2. In this symposium chaired by one of my PhD students with me as discussant, hear from several different academic and practitioner teams about how they are using natural language processing, a data science technique for utilizing text data in quantitative analyses.
- SIOP Select: A SIOP Machine Learning Competition: Learning by Doing on Friday, April 20 at 10:00AM in Chicago 6. Several months ago, nearly 20 teams competed to get the best, most generalizable prediction in a complex turnover dataset. The four winning teams are presenting in this session. In full disclosure, we weren’t one of them! Team TNTLAB was right middle of the pack – yet our R^2 was a full .02 lower than the winning team! We’re definitely going to be attending this one to learn what we’re going to do next year.
- Where Do We Stand? Alternative Methods of Ranking I-O Graduate Programs on Friday, April 20 at 11:30AM in Gold Coast. In the current issue of TIP, we got a whole bunch of new ranking systems for I-O psychology graduate programs, including one put together by TNTLAB! In this session, you get to learn exactly where these ranking systems came from. I expect some stern words and maybe even some yelling from the audience, so this is definitely one to attend!
- Employee Selection Systems in 2028: Experts Debate if Our Future “Bot of Not?” on Friday, April 20 at 3:00PM in Chicago 9. In this combination IGNITE and panel discussion, each presenter (including me!) will share their vision of just how much artificial intelligence will have taken over selection processes in organizations by 2028.
- Technology-Enhanced Assessment: An Expanding Frontier on Friday, April 20 at 4:00PM in Gold Coast. This is my first “optional” session of the conference, but it looks to be a great one! Learn how PSI, Microsoft, ACT and Revelian are innovating in the assessment space. I hope to learn about the newest of the new!
- Make Assessment Boring Again: Have Game-based Assessments Become Too Much Fun? on Saturday, April 21 at 10:00AM in Huron. In this panel discussion, a group of practitioners and one lone wolf academic (me!) will discuss the current state of game-based assessments and how I-O is (and is not) adapting to them.
- SIOP Select: New Wine, New Bottles: An Interactive Showcase of I-O Innovations on Saturday, April 21 at 11:30AM in Chicago 6. This session is my brainchild, so I am really hoping it is fantastic! I’ve invited three I-O practitioners that I think represent the height of innovation integrating computer science and I-O psychology to reveal just how they did it. But they can’t just talk the talk – they’ve got to walk the walk. We’ll see live demos in front of the whole room with naive audience members which I will select live from the audience. No plants, I’m keeping them honest! But that means the tech has got to be perfect! Check it out!
- Forging the Future of Work with I-O Psychology on Saturday, April 21 at 1:30PM in Superior A. In this session, learn about the results from the SIOP Futures Task Force (which I was on and am leading next year!) exploring how I-O psychology and SIOP need to adapt to survive in this increasingly constantly changing world of work.
- IGNITE + Panel: Computational Models for Organizational Science and Practice on Saturday, April 21 at 3:00PM in Sheraton 5. This is my second optional session, and I’m going mostly because I want to know what an IGNITE session about computational models will look like! This is a crazy idea even on the face of it! But Jay Goodwin (USARI) and Jeff Vancouver are on it, so I know it’s going to be amazing!
I hope to see you there! Safe travels to all!